——by Everfades
鉴于笔者水平有限,部分讲解可能存在不规范,于此还望见谅,如果您有宝贵的意见或建议,请发邮件至:everfades1218@gmail.com或everfades@foxmail.com
希望大家能从这篇笔记中取得一些收获!
(⚠在使用Typora阅读前,请将文件→偏好设置→Markdown→内联公式 勾选上,以免显示出错!)
一.什么是TCP?
在研究TCP粘包之前,我们先来看看什么是TCP:TCP全称Transmission Control Protocol,也叫传输控制协议,一般和IP组合成TCP/IP网络核心,其在网络通信中起到了不可或缺的作用。一般来说TCP的流程如下:
1.三次握手(建立连接)
- 客户端 -> 服务端:SYN(请求连接)
- 服务端 -> 客户端:SYN + ACK(同意+确认)
- 客户端 -> 服务端:ACK(准备就绪)
2.四次挥手(断开连接)
- 客户端发出FIN,表示不再发出数据
- 服务端回复ACK,表示已经收到关闭请求
- 服务端发出FIN,表示我方的数据已经发完,可以关闭
- 客户端回复ACK,表示确认断开
通过三次握手四次挥手,TCP保证了数据不丢包,不错乱,不重复。
二.什么是TCP粘包、拆包?
TCP的数据收发采取的是字节流协议,既然是流协议,为什么还会有包的概念呢?其实这个所谓的TCP粘包,是体现在服务端的”粘包”。而粘包又分为发送粘包和接收粘包,前者是指发送方缓冲区数据攒多帧一次性发出,导致多个逻辑包拼成一块;而后者是指接收缓冲区积攒多条数据,一次读取拿到多个数据包。
无论是哪种粘包,最后都会导致在recv的时候一次性拿到多条数据,无法分清边界。
拆包和粘包恰恰相反,拆包是把一份完整的单个业务数据包,拆成多段分次收到,一次 recv 只拿到部分片段。
三.为什么会出现粘包、拆包的情况?
出现粘包的核心原因就是TCP 是面向字节流的协议,协议层本身不携带应用消息边界,操作系统只负责收发连续字节流,无法区分应用层一条消息的起止位置。
举个例子,发送方发送了两条消息:
send("Hello")
send("World") 但是TCP只看到了连续字节流:
HelloWorld 显然,接收方一次 recv() 到多少字节,并不等于发送方一次 send() 发了多少字节。
实际触发粘包分为两类场景:
- 发送侧合并粘包:
①开启 Nagle 算法时系统主动缓存小包、等待合并发送;
②短时间多次发送少量数据,发送缓冲区尚有富余,内核将多段应用数据缓存后封装为单个 TCP 报文发送;
- 接收侧合并粘包:
对端一个 TCP 报文携带多条应用数据存入本机接收缓冲区,应用单次recv读取缓冲区全部数据,一次性拿到多条业务消息,形成粘包。
Nagle 算法、发送缓冲区攒包、接收缓冲区批量读数据,都只是粘包的常见诱因,而非本质原因。
拆包的原因也类似:其本质原因是 TCP 是字节流协议,加上 MSS/MTU、缓冲区、窗口控制、拥塞控制和接收方读取大小等因素,导致一条应用层消息可能被分成多次接收。其中,一般MTU是路由器的最大传输单元,来定义一个数据包的大小,当数据包大小超过MTU限制的时候,会按MTU分成几个包,对于家庭和办公路由器,MTU的默认大小一般为1500字节。
四.如何解决TCP粘包拆包问题?
一般有三种解决办法:定长分割法,分隔符法,长度字段法。
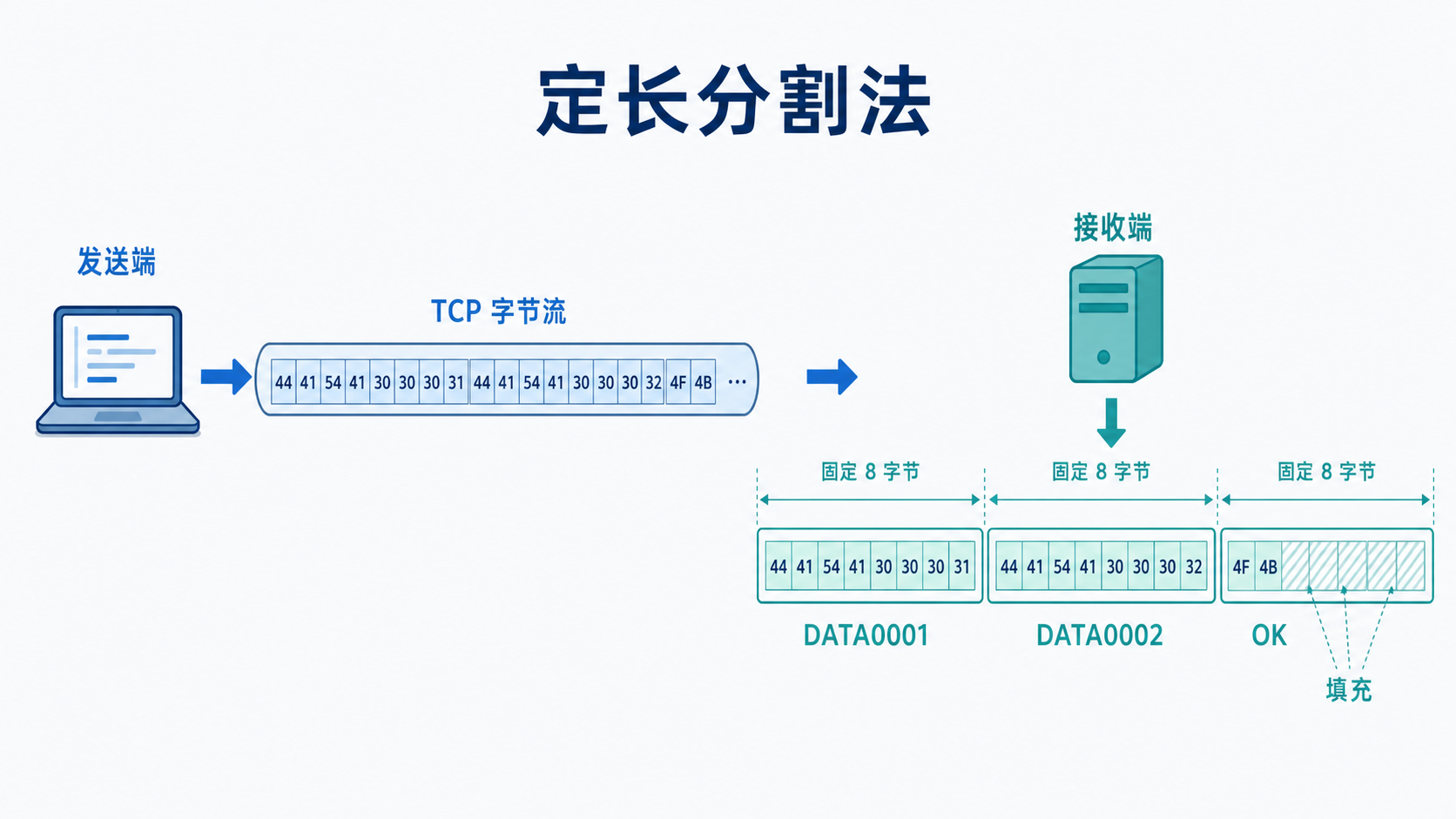
1.定长分割法:
顾名思义,定长分割法就是在接收消息的时候按照固定的长度接收消息,不足的部分会补空格或其他填充字符,这样无论数据包被如何分割,接受放都能够按照固定的长度来解析,我们常见的FTP(File Transfer Protocol)就是采用这种方案(FTP的底层传输一般也是基于TCP的)。
优点:解析稳定,不容易出问题。
缺点:浪费空间,效率较低。
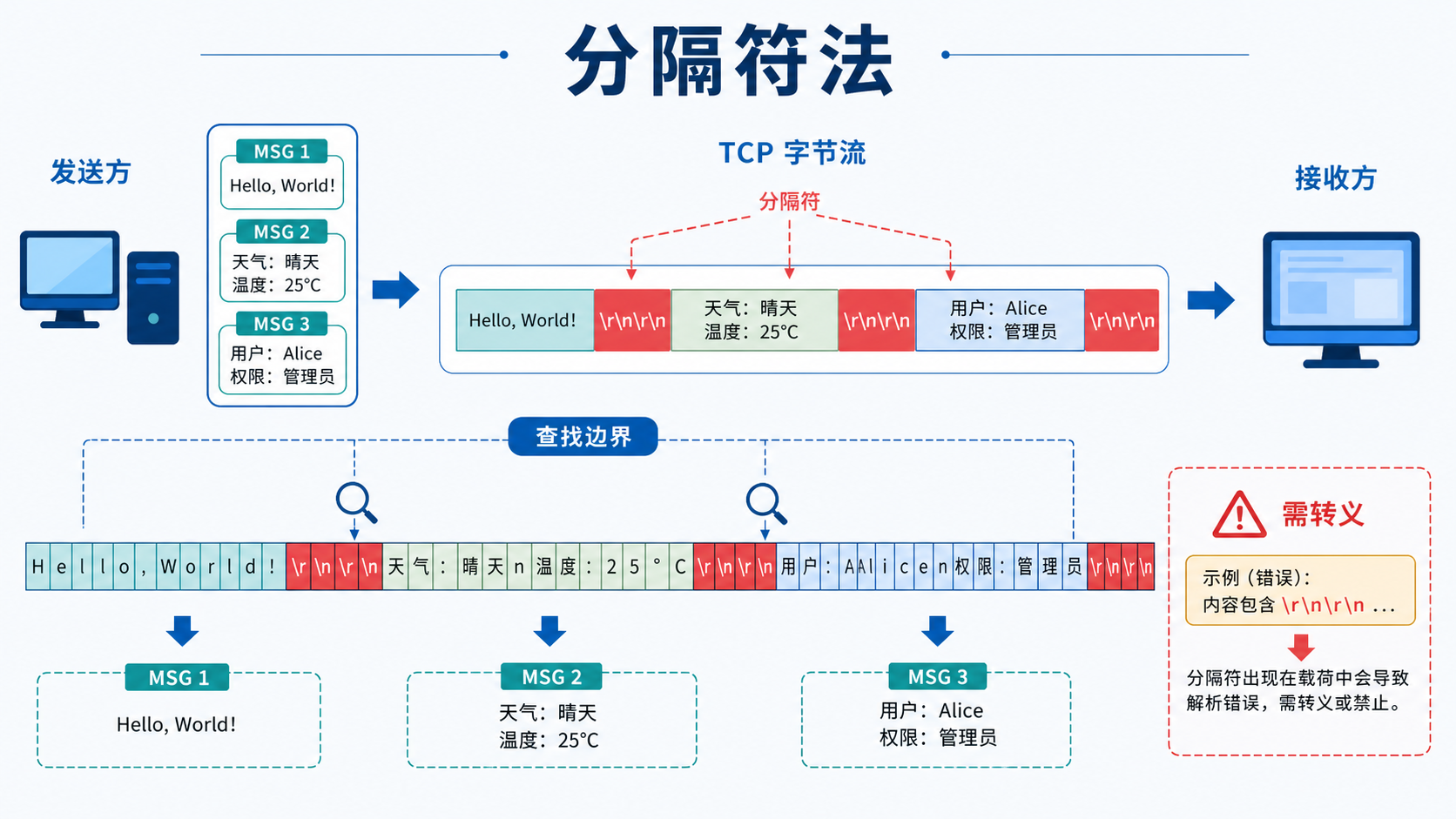
2.分隔符法
第二种就是采用分隔符,我们会定义一个特殊的分隔符,每发出一条消息,就在消息末尾添加这个分隔符,接收方通过寻找这个分隔符来确定消息的开始和结束。
在电子邮件传输协议SMTP(Simple Mail Transfer Protocol)中就是采用的这个方案,它采用连续的两个换行+回车表示邮件的结束。
优点:泛用性强。
缺点:分隔符选择不当,在消息中出现会导致意外分隔。
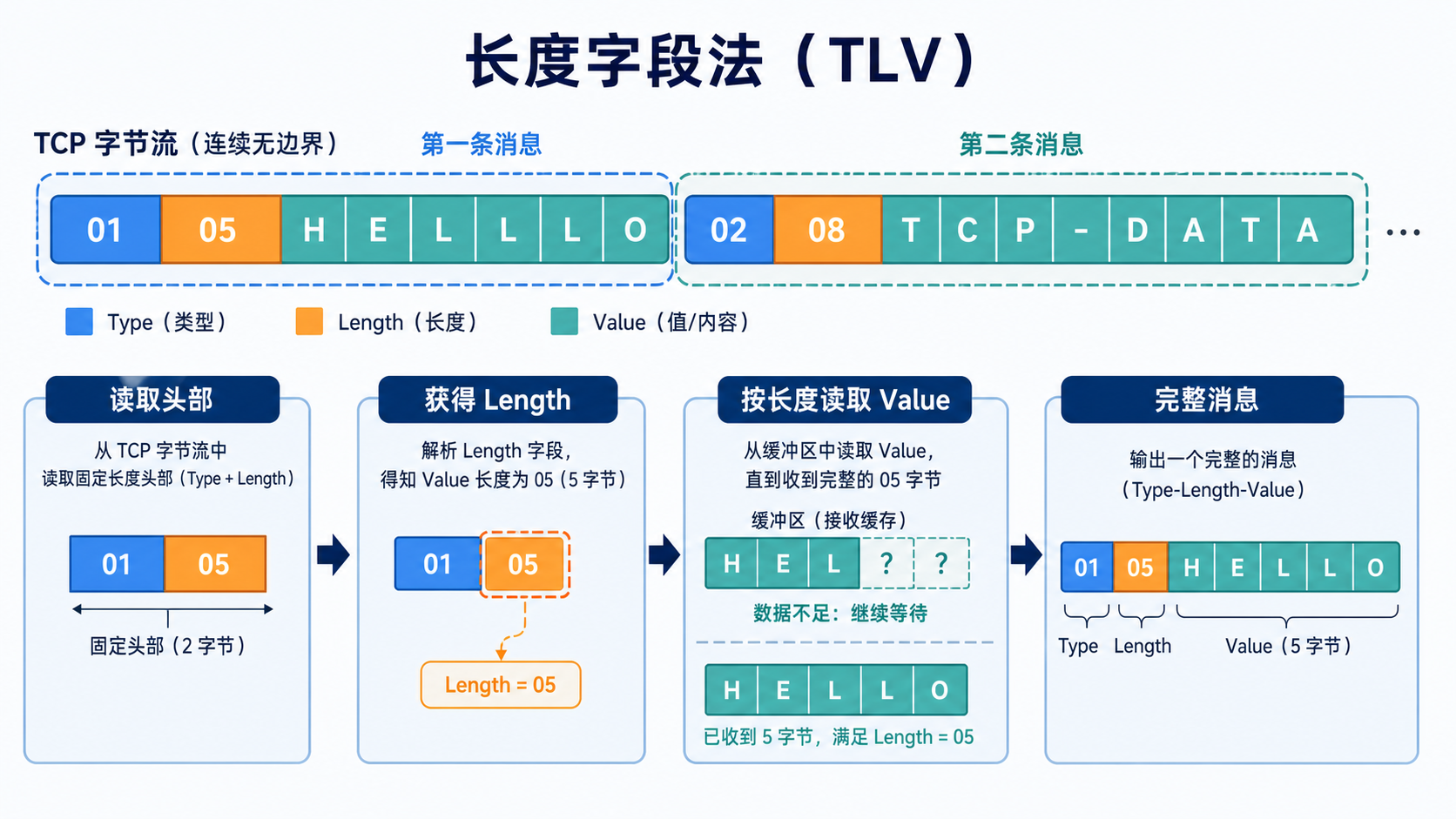
3.长度字段法
这种是目前业界最主流,最标准的做法,其在消息头加一个字段来存储消息的长度,接收方在收到消息时,会首先读取这个长度,再根据这个长度读取对应长度的数据,这种方式最流行的实现方式是TLV(Type-Length-Value)。
当接收方读取到Type时,说明一个新的协议数据包开始了(类似于Java class中的开始字符JAVA BABE)。Length字段存储了数据包的长度,接收方只要按照这个长度读取后续的字符即可,读取完就会获得一个完整的包,还没接受够那就继续等,直到接受足够长度的数据为止。Value就是数据内容。