——by Everfades
(⚠️必读)本笔记主要针对于较为核心的六大算法(主观向) 枚举、贪心、分治、回溯、搜索、dp(动态规划) 进行记录,主要面向想要参加算法竞赛,具有一定编程基础,希望提升算法能力的同学,这里会通过算法辅以竞赛真题进行讲解。虽然算法有很多种,但是基本所有的其他算法,都是可以从上述的六大算法中衍生出来的。
鉴于笔者水平有限,部分示例以及代码可能存在不规范的书写,甚至存在纰漏,于此还望见谅,如果您有宝贵的意见或建议,请发邮件至:everfades1218@gmail.com或everfades@foxmail.com
希望大家能从这篇笔记中取得一些收获!
(⚠在使用Typora阅读前,请将文件→偏好设置→Markdown→内联公式 勾选上,以免显示出错!)
Part 1:枚举
📕枚举
在许多教程中中,枚举算法经常会和遍历,暴力,甚至brute force算法相混淆,在接下来的笔记中,会详细的对枚举算法进行剖析,揭示枚举算法的核心所在。
首先,我们不妨对枚举算法下个定义
枚举算法↓
在某个包含可能的解的集合中,按某个顺序依次检验元素,并用题目所给的约束条件进行校验或计算
这么说可能有点抽象,我们可以举个例子来说明一下:给定一个数组,判断是否存在奇数,那么在这个例子中,集合就是给定的数组,顺序可以是正向或者反向都行,条件就是元素是否为奇数。
对于这种是否存在的问题,我们可以称其为 any of 枚举,或者 find if 枚举,目的在于找到一个符合条件的元素。当然我们也可以变形一下,推广出 all of 枚举, none of 枚举,在本例子中,即所有元素都是奇数( all of ),或所有元素都不是奇数( none of )。对于这三种枚举来说,朴素的写法需要设置一个 flag 来标注是否符合题意,这里就不过多展开了。我们更多会使用STL库中的函数,比如 any_of ,all_of ,none_of ,find_if , max_element , min_element , accumulate 等,这些函数都是 “ 泛型模板函数 ” ,可以用于任意类型的数据,以上算是枚举最基础的模型。
我们再来看个进阶一点的:在一个数组中,判断是否存在子数组?
原 数 组: E V E R F A D E S
目标数组: E V A
子数组的意思是,从原数组中 按顺序取出 若干个元素,组成一个新数组等于目标数组,那么我们可以套用基础的模型,相信有聪明的同学已经明白解法了,我们可以用 find if 的模型去判断第一个元素,查找成功则再去判断第二个元素,查找成功则再去判断第三个元素……
那么这里有一个问题,存在子数组的的判断条件,或者说设置的 flag 是什么呢?我们直接来看模板函数
template <typename T>
bool subMatch(constT &arr, const T &target) {
size_t idx = 0;
for (auto &elem : arr) {
if (elem == target[idx]) {
if (++idx ==target.size()) return true;
}
}
return false;
}
从这个函数模板中,我们不难看出,在遍历 arr 中的元素时,每当 elem ==target[idx] 的返回值为 true,idx的值都会 +1 ,直到 idx 的值与 target.size 相等,即子数组的大小与我们的目标数组的大小相等时,再 return true ,代表找到了这样一个子数组,否则返回 false。
再来说对于枚举的优化,比如回文串的枚举 ( 关于回文串,有一个经典的笑话,(()) 不是回文串,())( 才是 )
int n = str.size();
for(int i = 0; i < n; i++){
if(str[i] != str[n - i - 1]){
return false;
}
}
根据定义,回文串的每个字符应该和它对称位置的字符相同,因此我们只需要枚举前一半就可以了,因为后一半的结果和前一半一定是相同的
int n = str.size();
for(int i = 0; i < n / 2; i++){
if(str[i] != str[n - i - 1]){
return false;
}
}
最后再来说一个常见的写法——按位枚举:枚举一个整数的每一位,然后进行题目要求的判断。( <— 这个用到的比较多 )
for( ; x; x /= base){ //base 代表进制数
int digit = x % base;
//do something
}
如果我们将枚举出的每一位存储到数组中,那就是将整数转化成其他进制
vector<int> toDigits(int x, int base) {
vector<int> digits;
for( ; x; x /= base){
int digit = x % base;
digit.push_back(digit); //在队列尾部插入,而不是像数组一样在头部插入,可以少一步翻转
}
return digits;
}
再通过另一个函数,我们还能将数组还原回原来的整数
int toDigit(vector<int> &digits, int base) {
int x = 0;
for(int i = digits.size() - 1; i >= 0; i--) {
x = x * base +digits[i];
}
return x;
}
最后,我们应该为枚举算法讨个公道,它并不等价于暴力算法,因为暴力这个词是相对的,有些题它的正确解法就是枚举;它也不等价于遍历算法,因为遍历的意思是按某个顺序访问数据结构中的所有元素,而枚举算法显然更为泛化,它可以对任意集合进行枚举。另外,后面的回溯算法本质上也是一种枚举,因为回溯算法的核心其实也是枚举所有解的集合,接下来我们通过10道练习题来巩固一下枚举算法。
🖊枚举练习
Tips:ctrl + 单击蓝色链接可直接跳转至题目
-1.luogu P10424[蓝桥杯 2024 省 B] 好数👍
不难看出,在本题中,我们只需要对1~N中的每一个数字的每一位进行按位枚举即可,我们可以设置一个好数个数的计数器 goodCount,设置一个 bool 类型的 isGood,如果在按位枚举的过程中有某一位不满足条件,则将 isGood 设置为 false,并退出后续循环,两个嵌套循环结束后,打印 goodCount 的值,具体实现如下:
#include<bits/stdc++.h>
using namespace std;
typedef long long ll;
int main(void) {
ll n;
cin >> n;
ll goodCount = 0; //好数的个数
bool isGood = true; //flag
for(int i = 1; i <= n; i++) {
isGood = true;
ll index = 1; //第一位是奇数
ll x = i;
while(x) {
ll digit = x % 10; //用digit提取出最低位
if (index % 2 != digit % 2) {
isGood = false;
break;
}
index ++;
x /= 10;
}
if (isGood) {
goodCount++;
}
}
cout << goodCount << endl;
return 0;
}
![1枚举P10424 [蓝桥杯 2024 省 B] 好数](https://picbeds-1403930428.cos.ap-beijing.myqcloud.com/%E7%AE%97%E6%B3%95%E6%80%9D%E6%83%B3/1%E6%9E%9A%E4%B8%BEP10424%20%5B%E8%93%9D%E6%A1%A5%E6%9D%AF%202024%20%E7%9C%81%20B%5D%20%E5%A5%BD%E6%95%B0.png)
-2.lanqiao[蓝桥杯 2023 省 A]幸运数❤
这是一道结果填空题,在评测机上,我们只需要 cout 出题目要求的结果即可,这就意味着我们可以暂且忽略评测机限制的时空复杂度,只要能求解出答案即可。对于本题而言,我们可以采用最朴素的做法,直接从1枚举到1e8,设置一个幸运数计数器 luckyCount ,设置一个 digitCount 用于计算位数,并设置左右两边求和的数leftNum,rightNum,以及位数的中值half,实现如下:
#include<bits/stdc++.h>
using namespace std;
typedef long long ll;
int main(void){
ll luckyCount = 0;
for(ll i = 1; i <= 100000000; i++){
ll digitCount = [](ll x){ //使用lambda 表达式
ll cnt = 0;
for(; x; x /= 10) cnt++;
return cnt;
}(i);
if(digitCount &1) continue; //digitCount &1 的意思是,若 digitCount 是奇数,其二进制的个位一定为1,那么 &1 的结果为true
if([](ll x, ll digitCount){ //使用lambda 表达式
ll half = digitCount >> 1;
ll leftNum = 0,rightNum = 0;
for(ll i = 0; x; x /= 10, i++){
if(i < half) leftNum += x % 10;
else rightNum += x % 10;
}
return leftNum == rightNum;
}(i,digitCount))luckyCount++;
}
cout << luckyCount << endl;
return 0;
}
我们先在自己的计算机上 run 一下代码,避免TLE

运行的结果为 4430091,我们只需要在评测机上打印结果就可以了
#include<bits/stdc++.h>
using namespace std;
int main(void)
{
cout << 4430091 << endl;
return 0;
}
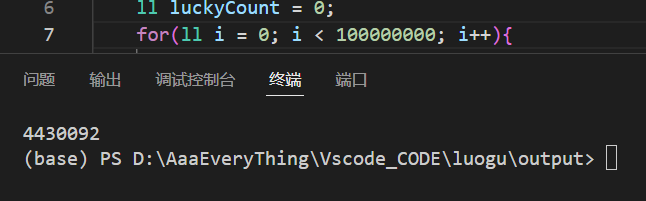
⚠️注意:本题有一个比较容易被忽略的点,那就是在第六行的 for 循环中,有同学可能会写成
for(ll i = 0; i < 100000000; i++);
乍一看似乎没有问题,二者都是循环100000000次,但是实际上,在 lambda 表达式传值的时候,i = 0 会被错误的传递进去,它会顺利通过 &1 的判断,最后导致输出的 luckyCount 比正确答案多一,错误结果如下:
-3.lanqiao[蓝桥杯 2021 省 B]卡片🎴
我们知道,小蓝0~9的卡片每张都有2021张,我们可以从 1 开始遍历,写一个死循环,对这些数字的每一位进行按位枚举,对枚举到的数字,卡片数量 – 1,直到某一个数字的卡片数量为 0 ,代表无法拼成这个数字,那么我们输出它的前一位 i – 1 即可。
下面给出了一种朴素的做法,在 cards[digit] == 0 时,我们break出当前循环,但我们只能跳出第一层,而无法跳出第二层循环,因此我们需要设置一个 flag 并初始化为 false,当 cards[digit] == 0 时,我们令 flag = true ,在外层循环中判断,当 flag == true 的时候,输出 i – 1 并再break一次,这样就完成了跳出循环,实现如下:
#include<bits/stdc++.h>
using namespace std;
int main(void){
vector<int> cards(10,2021);
for(int i = 1; ; i++){
bool flag = false;
for(int j = i; j; j /= 10){
int digit = j % 10;
if(cards[digit] == 0){
flag = true;
break;
}
cards[digit]--;
}
if(flag == true){
cout << i - 1 << endl;
break;
}
}
return 0;
}
同样的,我们也可以采用第二题的 lambda,实现如下:
#include<bits/stdc++.h>
using namespace std;
int main(void){
vector<int> cards(10,2021);
for(int i = 1; ; i++){
if([&](){
for (int d = i; d; d /= 10){
int digit = d % 10;
if (cards[digit] == 0) return true;
cards[digit]--;
}
return false;
}()){
cout << i - 1 << endl;
break;
}
}
}
-4.lanqiao[蓝桥杯 2024 省 B] 小球反弹 ⚽
按照题目指引的思路,我们需要计算小球反射的点并反射速度,这样的几何运算极其复杂,涉及的条件也十分的多,我们不妨转换一下思路🤓👆,我们现在需要计算的是小球是否能否到达 “原点” ,我们可以将原长方形向右翻转复制一份,再向下翻转复制一份,这样我们就获得了一个长为 343720 * 2 ,宽为 233333 * 2 的长方形,它的四个角都是 “原点” ,那么我们便可以让小球一直沿着原路线前进,并且不断的复制这个长方形,直到小球刚好到达第一个原点为止,最后用勾股定理计算出小球运动的距离即可,实现如下:
#include<bits/stdc++.h>
using namespace std;
typedef long long ll;
int main(void){
ll dx = 15,dy = 17;
ll width = 343720 * 2, hight = 233333 * 2; //新长方形的长,宽,为原长宽的二倍
for(int t = 1; ; t++){ //无限循环
//这里t * dx % width == 0 代表小球触到底边,t * dy % hight == 0 代表小球触到右边,同时满足则代表到达“原点”
if(t * dx % width == 0 && t * dy % hight == 0){
// << fixed <<setprecision(2) 代表设置输出到小数点后两位,hypot 为勾股定理计算函数
cout << fixed << setprecision(2) << hypot(t * dx, t * dy) << endl;
break;
}
}
return 0;
}
-5.luogu P1149 [NOIP 2008 提高组] 火柴棒等式🔥
NOIP 2008年的提高组 ( 这真是提高组吗?),这道题的要求是,对于一个给定的 n ,求能拼成符合题意的等式的数量,那么我们不难想到枚举算法。题干还有,A + B = C 和 B + A = C 视为不同的等式,那么我们就对 A 和 B 都进行枚举,设置一个用于计算消耗了多少火柴棒的函数 cnt() ,最后判断一下if(cnt(A) + cnt(B) + cnt(C) + 4 == n) 即可,如果相等则令计数器 ans++ ,思路非常清晰。
但是本题的关键点在于如何确定枚举的范围,观察输入格式,发现题目所给出的 n 的范围为 1 ≤ n ≤ 24,并且我们还需要 4 根火柴棍构成 “+” 和 “=” ,所以实际我们能用来构成数字的只有20根火柴棒,那么我们便需要找到一个最大的数字作为枚举上界。首先我们要明确一点,那就是我们的火柴棒,使用的优先级永远是增加 “数位”,而不是增大 “数字”,假设我们现在有 6 根火柴棒用来构成一个数字,那么显然 “111” 必然是最大的解,没有其他情况(大家可以试一下)。但假设我们有 7 根火柴棒,构成 “111” 之后,余下的一根没办法再增加 “数位” ,那么我们再考虑增加 ” 数字 ” ,最大数为 “711”,这里不多证明。对于 n == 24 而言,我们能找到的A(B)最大的等式为 ” 711 + 1 = 712″(消耗23根火柴棒),那么我们可以再稍微增加枚举上界到1000,这样是比较安全的,代码实现如下:
#include<bits/stdc++.h>
using namespace std;
int main(void){
int n;
cin >> n;
int digits[] = {6, 2, 5, 5, 4, 5, 6, 3, 7, 6}; //每个数字所需要的火柴棒数
auto cnt = [&](int x){ //计算数字所需要的火柴棒函数
if(x == 0)return digits[0];
int num = 0;
for(; x; x /= 10){
num += digits[x%10];
}
return num;
};
int ans = 0;
for(int a = 0; a <= 1000; a++){ //枚举
for (int b = 0; b <= 1000; b++){
int c = a + b;
if (cnt(a) + cnt(b) + cnt(c) + 4 == n) ans++; //符合条件则ans++
}
}
cout << ans;
return 0;
}
假设枚举范围没有判断好,导致TLE了,那应该怎么办呢🤔? n 的范围为 1 ≤ n ≤ 24 ,输入的数据范围比较小,那我们就可以将所有的答案在自己的计算机中运行出来,再将答案保存到一个 answer 数组里,对于不同的 n 输入,我们直接返回 answer[n] 即可,对于不同的 n ,答案 run 出来的过程就不多赘述,具体实现如下:
#include<bits/stdc++.h>
using namespace std;
int main(void){
int n;
cin >> n;
int answer[] = {0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 2, 8, 9, 6, 9, 29, 39, 38, 65, 88, 128};
cout << answer[n] << endl;
return 0;
}
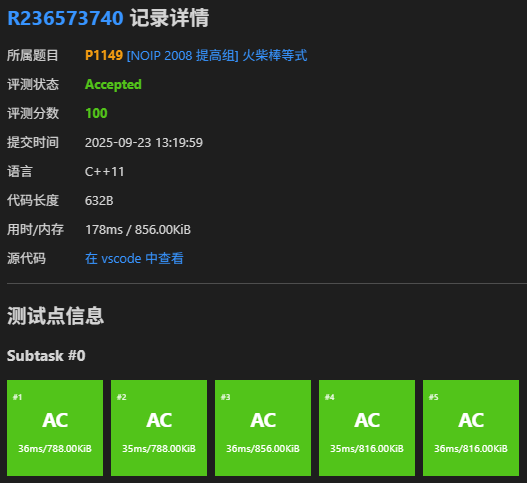
两种答案均顺利AC,我们刚才所提到的第二种将答案保存到数组中的方法,就叫 “打表”🤓👆,这种方法一般适合输入数据范围小,且比较容易 TLE 的题目中。
📕前缀和-prefix
给你一段数组,让你求一段区间 L 到 R 的和,我们只需要枚举从 L 到 R 即可
int sum = 0;
for(int i = L; i <= R; i++){
sum += arr[i];
}
但如果有 M 次查询呢🤔?
int sum = 0;
while(M--){
for(int i = L; i <= R; i++){
sum += arr[i];
}
}
每次都查询,时间复杂度就变成了,查询次数 × 区间长度,即O(MN),这显然效率太低了❌,为了更加高效的处理查询请求,我们便会采用一种名为 ” 前缀和 ” 的算法。
vector<int> prefix(n);
for(int i= 0; i < n; i++){
if(i) prefix[i] = prefix[i - 1];
prefix[i] += arr[i];
}
我们也可以用C++98中引入的一个STL函数 : partial_sum(),它位于 numeric库中,下面的代码和上面是完全等价的:
vector<int> prefix(n);
partial_sum(arr.begin(), arr.end(), prefix.begin());//参数分别为:起始,终止,目标位置
假如我们要进行反向遍历,那么只需要写成 partial_sum(arr.rbegin(), arr.rend(), prefix.rbegin()); ,简单修改一下迭代器即可。
接下来说查询,比如要查询 L 到 R 的区间和,sum(L, R) = prefix[ R ] – prefix[ L – 1 ]; 假设 L = 3,R = 6,那么prefix[ 3 ] = 1 + 2 + 3 , prefix[ 6 ] = 1 +2 + 3 + 4 + 5 + 6 , prefix[ 6 ] – prefix[ 2 ] = 3 + 4 + 5 + 6。但如果 L 是 0 ,那么 L – 1就越界了,这时我们有两种处理方法:
①:第一种是对 L == 0 的情况进行特判:L ==0 时,直接返回 prefix[ R ] 即可。
②:第二种则是在计算 prefix 时,下标从 1 开始计数,这样 L 的最小值也就是 1 ,L – 1 也就不会越界了。。
vector<int> arr(n + 1),prefix(n + 1);
for(int i = 1; i <= n; i++){
cin >> arr[i];
}
partial_sum(arr.begin(), arr.end(), prefix.begin());
我们也可以使用范围循环,两种均可,看个人喜好选择写法👍。
vector<int> arr(n),prefix(n + 1);
for(auto &x : arr) cin >> x;
partial_sum(arr.begin(), arr.end(), prefix.begin() + 1);
当然,我们也可以按照这个思路,将前缀和推广到前缀积和前缀异或:
前缀积:mul(L,R) = prefix(R) / prefix(L - 1);
(注:对于 int 类型的数据,2⁶⁴ 就溢出了,因此我们一般会对前缀积的结果进行取模运算,一旦取模,还原回来那就不是简单的逆运算了,这属于“乘法逆元”的范畴,会运用到费马小定理和快速幂😨,对于算法新手来说,这部分有一定难度,在此就不进行展开了,感兴趣的同学可以试着将这几个知识点结合起来)
前缀异或:xor(L,R) = prefix(R) ^ prefix(R - 1);
异或的运算如下:
True ^ False = True
False ^ True = True
False ^ False = False
True ^ True = False
即相异为真,相同为假,其逆运算同样为异或,少了很多麻烦。
我们再来看异或运算一个有趣的性质。
原 数 组:2 2 7 5 7 2 1 4 1 5
↓ ↓
↓ ↓
前缀异或数组:2 0 7 2 5 7 6 2 3 6
如果前缀异或数组中的两个元素相同,就代表这一段左开右闭区间(5,7,2)的异或和为零,其证明也非常简单:
我们假设 p[i] = p[j],也就是 a₁ ⊕ a₂ ⊕ a₃ ⊕ … ⊕ ai = a₁ ⊕ a₂ ⊕ a₃ ⊕ … ⊕ aᵢ ⊕ aᵢ₊₁ ⊕ … ⊕ aⱼ,再两边同时 ⊕ (a₁ ⊕ a₂ ⊕ a₃ ⊕ … ⊕ ai),因为异或运算率是相同为假,所以 0 = aᵢ₊₁ ⊕ … ⊕ aⱼ。
同样的,如果前缀异或数组中有多个数字相同,那么任选两个相同的数字所构成的区间内异或和都为 0。
其实这些不是累加的运算同样可以使用partial_sum来编写:
partial_sum(arr.begin(), arr.end(), xorsum.begin,
[](int prev, int cur){
return prev ^ cur
});
partial_sum的第四个参数可以接受一个二元操作函数,用于表示如何进行统计,这个函数的第一个参数是已经统计的结果,第二个参数是当前元素,所以我们只需要 return 一个 prev ^ cur 即可😎。
😋下面我们将 prefix 扩展到更高维度,我们可以用 prefix 的思想求出一个二维矩阵中任意一个子矩阵的和,我们之需要先对行和列分别求前缀和,这样这个二维数组中的元素就代表了左上角到当前元素位置的所有元素之和。那么求某个子矩阵之和,就是用右下角的前缀和减去左下角的前缀和,再减去右上角的前缀和,再加上左上角的前缀和(其实看图更直观一点):
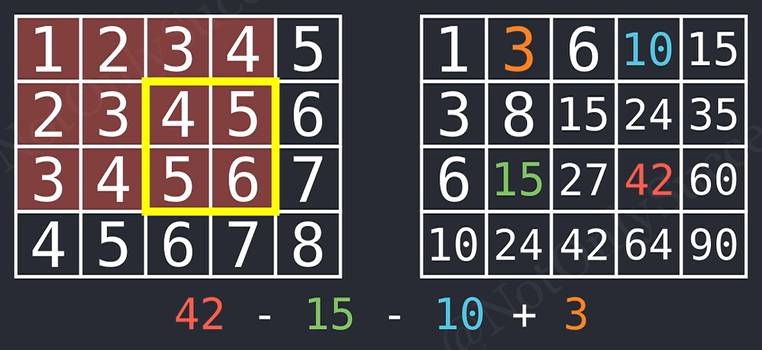
其背后所蕴含的其实是数学集合分支中的容斥原理,大家高中应该都学过,那么根据它,我们便可以推广到三维甚至更高维度的前缀和,在此就不过多赘述了,感兴趣的各位可以自行写一段代码尝试一下更高维的前缀和。
🖊前缀和-prefix练习
-6.luogu P12206[蓝桥杯 2023国B] 弹珠堆放🔺
本题是一道签到题,考察的重点就是前缀和,仔细观察这个金字塔,我们不难发现其规律:假设我们有金字塔的第 i 层,那么这一层的总弹珠数实际上等于
((1 + i) * i) / 2,是一个等差数列。因为是一道填空题,所以思路也十分简单,我们只需要设置一个很大的数 n ,确保金字塔绝对不可能到达第 n 层,再对形如
1,2,3,4,5,6,7,8,9…的数组做两次前缀和即可,最后遍历数组,如果数组元素大于target,输出其前一个元素的下标即可,实现如下:
#include<bits/stdc++.h>
using namespace std;
int main(void){
ios::sync_with_stdio(0),cin.tie(0),cout.tie(0);
int n = 10000; //设置一个很大的 n
int target = 20230610; //目标值
vector<int> a(n);
iota(a.begin(), a.end(), 0); /*iota是位于<algorithm>中的函数,其三个参数分别为【起始位置】【终止位置】【初始值】,iota会从初始值开始,按照指定的步长(默认为1)递增,直到达到或超过结束迭代器*/
partial_sum(a.begin(), a.end(), a.begin());
partial_sum(a.begin(), a.end(), a.begin());
for(int i = 0; i <= n; i++){
if(a[i] > target){
cout << i - 1 << endl; //a[i] > target 说明无法搭成这一层,所以输出上一层的下标
break;
}
}
return 0;
}
-7.LeetCode 42.接雨水💧
毒瘤面试题,某个大厂(ByteDance)最喜欢考察的算法题,其在LeetCode上作为红题,正确率却已经达到了惊人的65.7%,足可见这道题被多少人刷过。
那么我们来看这道题,以LeetCode上的图片为例,如果一个位置可以容纳雨水,那么它的两侧必须要有高于它的柱子,这个位置具体能容纳多少雨水,取决于其左右两侧各自最高的柱子取最小值再减去这个位置柱子的高度,在图中,黑色的部分为柱子,蓝色的部分为雨水。
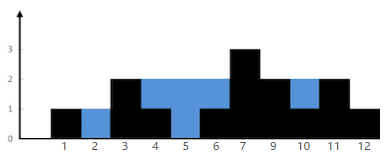
那么位置5的雨水量就等于min(左边柱子的最大值,右边柱子的最大值),即min(位置3,位置7)=2
,所以5位置的水量为2 – 0 = 2。思路已经清晰,那么接下来要解决的就是任意位置其左右两侧的最大柱子高度,我们可以先从前向后遍历,找出左侧到这个位置的最高柱子
,再从后向前遍历,找出右侧到这个位置的最高柱子。取min之后再减去当前位置的柱子高度即可。其他思路十分简单,就不多赘述了。实现如下:
class Solution {
public:
int trap(vector<int>& height) {
int n = height.size();
int ans = 0;
vector<int> leftMax(n), rightMax(n); //开两个vector
leftMax[0] = height[0], rightMax[n - 1] = height[n - 1]; //初始化边界,防止越界。(记得处理边界问题)
for (int i = 1; i < n; i++) {
leftMax[i] = max(leftMax[i - 1],height[i]); //从前往后遍历
}
for(int i = n - 2; i >= 0; i--){
rightMax[i] = max(rightMax[i + 1], height[i]); //从后往前遍历
}
for(int i = 0; i < n; i++){
ans += min(leftMax[i], rightMax[i]) - height[i]; //ans记录雨水总和
}
return ans;
}
};
📕差分
⚠虽然单独拆分出来作为一个算法,但必须强调的是,”差分”本质上是”前缀和”的逆运算,其是一种快速处理区间加减操作的算法,那么到底什么是差分呢?
显然,差分就是对某些元素减去前一个元素的值,也就是计算相邻两个数的差,因此叫做差分。差分的写法如下:
for(int i = n - 1; i >= 0; i--){
if(i == 0) d[i] = a[i];
else d[i] = a[i] - a[i - 1];
}
在C++标准库中也有一个函数
adjacent_difference(a.begin(), a.end(), d.begin());
其使用方法和partial_sum类似,在此就不再赘述了
接下来我们来看一个推论:对区间 [l , r] 区间内每个元素都增加 k,等价于对差分数组 l 的位置增加 k ,r + 1 的位置减 k。接下来我们举一个例子来看看这个推论有什么用。
假设原数组为 1 2 3 4 5,我们想在 0 ~ 3 的区间都 +2 ,显然朴素的做法是枚举0 ~ 3 位置的每一个元素都加2,这样经过 m 次查询后,复杂度是O(n * m),在数据范围较大的时候显然太慢了,1 2 3 4 5对应的差分数组为 1 1 1 1 1 -5(为了防止越界,可以多开一位),区间修改后的原数组为 3 4 5 6 5,对应的差分数组为 3 1 1 1 -1 -5, 可以发现,[0 , 3] 区间加2的操作,对应的就是在差分数组 0 的位置加 2 ,4 的位置 – 2。这意味着每次修改我们都只需要以O(1)的复杂度改两个位置,那么我们就可以对原数组先进行一次差分,再进行修改,最后进行前缀和还原为原数组,复杂度由O(n * m)降低到了O(n + m),可喜可贺!🥰
让我们继续推广到二位差分数组,如果我们对(x₁,y₁)到(x₂,y₂)的区间都 +k,就等价于对差分数组中(x₁,y₁) +k,(x₂+1,y₂+1) +k,(x₁,y₂+1) -k,(x₂+1,y₁) -k,这样就可以将原本需要n^2的枚举修改,优化到了O(1)的复杂度,可喜可贺!!!🥰🥰🥰
🖊差分练习
-8.Potyczki Algorytmiczne 2020 KOL ❤💛💙–
原题链接: https://pan.baidu.com/s/1x7WcXFJATeGxC-wm_XmxVw?pwd=0721 提取码: 0721
-9.luogu P13879[蓝桥杯 2023省JAVA A] 棋盘⚫⚪️
挖个坑在这里!
-10.luogu P10903[蓝桥杯 2024省C++ C]商品库存管理📦️
挖个坑在这里!
📕*单调性枚举
挖个坑在这里!
Part 2 : 贪心
📕贪心
你有无限多的数字 5 5 5 5 5 5 5 … ; 2 2 2 2 2 2 2… ; 1 1 1 1 1 1 1 … ;
如何选择最少的数字,让选择的数字之和 n 恰好满足 n == 27?最符合我们直觉的策略就是先贪心拿最大的数字,直到接近 n 但不超过 n ,然后剩下的再用同样的方式用更小的数字填补空缺,也就是需要5个5和1个2,这个思想对于这组数字来说是正确的,但是对于这个模型来说是浅显的、错误的。那么究竟什么是贪心呢?
首先让我们对贪心下一个定义👇
从 初始状态 到 目标状态
求一个 最佳方案
有多个 状态转移 方式 (改变当前状态的方式)
仅根据 当前状态 来制定的 策略
称之为 贪心
emm…有点看不懂,这些名词都是什么意思?那就让我们以刚才那个问题为例进行解释
状态:已选择数字之和
初始状态:0
目标状态:n
最优方案:个数最少
状态转移:+1,+2,+5
策略:仅根据当前的和,优先选最大的数
这些概念都清楚之后,我们不妨重新审视我们之前贪心的策略,符合我们直觉的策略就是先贪心拿最大的数字,但我们应该如何证明我们的策略是正确的呢?
我们来尝试着证明一下:因为我们是拿最大的数字,直到接近 n 但不超过 n ,我们可以使用反证法,设当前状态为x,x+5≤n,根据我们的策略,应该选5。
那么我们假设:在这种情况下有比选5更好的方案,比如选择2,再假设选择了2后,后续还会选5,由于选择顺序没有关系,所以先选2再选5和先选5再选2是等价的,因此这个假设下选2并不比选5更好,假设不成立❌
所以我们看另外的情况,在我们选了2之后,剩下的状态转移只剩下+2和+1,因为x + 5 ≤ n, 所以我们可以:
- 假设目标是n = x+5,这种情况下最优解为|+2,+2,+1|,比直接选5差,所以不成立
- 假设目标是n = x+6,这种情况下最优解为|+2,+2,+2|,比|+5,+1|差,所以不成立
- 假设目标是n = x+5+2i,这种情况下最优解就是在n = x+5的基础上再选 i 个2,一共需要3 + i个数,比选5后再选 i 个 2,也就是1 + i个数要差,所以不成立
- 同理可证n = x+6+2i也不成立
因此在这个情况下,选 2 都不可能会比选 5 要好,同理也可证明选1也不会比选5要好,所以在x+5≤n时,选5是最优解。
我们刚才在做的事,其实是大家初学贪心算法时极其容易忽略,但却是最重要的一部分。将题目稍加改动,每次选择的数字从1、2、5改为1、3、4、5,并且目标改成n == 7,这种情况下根据我们的策略,会选择5、1、1,但更优解是3、4,显然策略不成立。
由此,我们便可以大致了解贪心问题的解题步骤
- 制定某个贪心的策略
- 证明这个策略的正确性
严谨的讲,贪心并不是一种严格意义上的算法,而是一个思想或者策略,它没有具体的模板和模型,但我们可以通过一些经典的贪心例子,来寻找一些启发,由此来帮助我们快速找到如何制定贪心的策略,以及如何快速证明其正确性。下面我们就来看两个比较经典的例子。
集合选择问题(长文本警告)
有 n 个开区间[lᵢ,rᵢ],在保证选择的区间两两不重叠的前提下,选择尽量多的区间
[4,6] [6,8] [2,5] [3,6] [1,3] [5,6] [0,8] [4,5],比如在这 8 个区间中选择最多的区间,是他们互不重叠,由于区间的选择顺序无关,所以我们想到可以先进行排序,比如我们以左端点从小到大排序,得到[0,8] [1,3] [2,5] [3,6] [4,5] [4,6] [5,6] [6,8],然后依次选择,我们会发现有一个特别长的区间[0,8]会被第一时间选择,就无法选择其他区间了,显然这么做不对。我们再尝试以右端点从小到大排序,得到[1,3] [2,5] [4,5] [3,6] [4,6] [5,6] [0,8] [6,8],然后依次选择:选择[1,3],去掉在集合区间内与它有重叠的区间,得到[4,5] [3,6] [4,6] [5,6] [6,8],再在剩余的区间中选择第一个[4,5],再次去重,得到[5,6] [6,8],选择[5,6],得到[6,8],最后选择[6,8],这样我们就获得了[1,3] [4,5] [5,6] [6,8],这样子看起来是正确的,接下来我们进行证明:
和区间0不相交的区间一定满足以下特征:
- 在 0 的左边 即 r ≤ l₀
- 在 0 的右边 即 l ≥ r₀
由于我们已经按照左端点递增排好了序,因此不可能存在 1. 的情况,因此只剩下了 2. 这种可能,也就是选择了区间 0 后,剩下的可选区间一定是l ≥ r₀的,我们将这个子集称之为,而选区间1时,对应的集合就是,而由于是小于等于的,因此的集合必然包含,以此类推,也必然包含任意的,而当我们选择一个区间后,剩下的可以认为是另一个同等规模的子问题,因为包含了其他的,因此必然有,因此选择第一个区间是最佳策略
再让我们总结一下启发:
- 如果选择与顺序无关,可以尝试sort
- 区间的排序可以用左端点、右端点、中点、长度等排序
- 贪心的策略是不断尝试出来的,一个策略不行就换另一个,证明策略不行最简单的方法就是找一个反例
- 对于求最大集合的问题,我们只需要证明选择A后,剩余选项集合S[A],包含其他的S[i],就可以证明贪心的正确性
最后,我们再回顾一下问题的抽象来加深一下印象:
- 状态:已选区间的集合
- 初始状态:空集合
- 目标状态:无法再选择
- 最优方案:最大集合
- 状态转移:选择一个不重叠的区间
- 策略:按右端点排序后,仅根据已选择的右端点选择第一个不重叠的区间
截止日期问题
问题如下:
有 n 个任务,每个任务都有截止时间 d[i] 和 收益 s[i]
每个任务都需要 1 天时间完成
问最多可以拿到多少收益
这道题与顺序无关,所以我们还是先尝试一下排序,最直接的想法就是按照收益从大到小排序,哪个收益高先做哪个↓
| 截止日期 | 3 | 3 | 1 | 2 |
|---|---|---|---|---|
| 收益 | 9 | 8 | 2 | 1 |
不难看出,收益为9和8的任务在第三天才截止,但我们在前两天就做完了,最后还能空余一天,但由于收益为2和1的任务已经截止了,导致我们最后一天被白白浪费了。
那如果按照截止日期排序呢?
| 截止日期 | 1 | 2 | 3 | 3 |
|---|---|---|---|---|
| 收益 | 2 | 1 | 9 | 8 |
如果按照时间顺序做,则可能导致前期的时间会浪费在低收益的任务上,导致高收益的任务没时间做,显然也不是最优的。
既然常规思路无法解决问题,那我们就尝试反向思考,先确定最后一天做什么,再确定倒数第二天做什么,一直倒推到第一天,
因此,我们最后一天要做的肯定是还在截止时间里且收益最大的
| 9 |
|---|
倒数第二天则做在截止时间里且收益倒数第二大的
| 8 | 9 |
|---|
倒数第三天则做在截止时间里且收益倒数第三大的
| 2 | 8 | 9 |
|---|
总结一下:这个问题给我们的启发是,当一道题正常思考没有思路时,可以考虑一下逆向思维,我们要对逆向思维祛魅,当作一种常规的解题技巧,不过是你众多尝试中普普通通的一种
最后,我们再抽象一下这道题的模型:
状态:第 i 天
初始状态:最后一天
目标状态:第一天
最优方案:最大收益
状态转移:选择在截至日期内的任务
策略:仅根据当前日期,选收益最大的
n个有序数组合并
给你 n 个从小到大的数组,把它们都合并成一个新的数组,合并完的新数组的规则是a[0] <= a[1] <= a[2] <= a[3] <= … <= a[n-1]。
而这 n 个数组的第一个元素是各自数组最小的,我们只需要在这些第一个元素中找到一个最小的,自然就是新数组的第一个元素。
贪心的策略是有了,但这道题考察的是如何编写程序,如果我们每次都找最小的数字把它删除,那复杂度就太大了,我们可以使用优先队列进行优化,在初始时先将元素放入优先队列。
(3, 1, 0)
(2, 2, 0)
(1, 0, 0)
其中记录的是(数字,第几个数组,第几个元素),这样我们就只需要每次从优先队列中获取最小的元素,然后根据后两个参数,将新的元素加入优先队列中,以此类推,直到原数组为空,由于我们每次获取的数据都是最小的,所以最终的顺序一定是有序的。
这道题给我们的启发是,优先队列是贪心的最佳搭档,因为贪心往往是一种”极端“的思想,我们经常会取最大值或最小值,而优先队列恰好又是内部有序的,因此在做贪心问题时,我们往往会搭配优先队列。
最后总结一下抽象模型:
状态:优先队列
初始状态:第一列放入优先队列
目标状态:优先队列为空
最优方案:新数组有序
状态转移:选取一个元素
策略:仅根据优先队列,选择最小的
在练习之前,让我们再回顾一下贪心问题的解题方式:
- 制定某个贪心的策略
- 证明这个策略的正确性
在证明策略正确性的过程中,不乏有一些非常简单一眼就能看出来的证明,也有的需要复杂的数学推导才能证明,这也是新手认为贪心十分简单,而高手才明白,贪心难起来会比其他算法难得多的原因。
在做题的过程中,我们要注重这些结论的推导,如果没思路就立马看题解,过一段时间后还是会忘,那样得到的提高几乎是微乎其微,比赛也几乎不可能出现同一道题目,希望大家在思考的过程中,能收获思维上的提升!
🖊贪心练习
-11.LeetCode 435.无重叠区间
本题实际上就是上述的集合选择问题,所以再此就不做赘述了,主要看代码的实现:
C++11:
class Solution {
public:
int eraseOverlapIntervals(vector<vector<int>>& intervals) {
//右端点从小到大排序
sort(intervals.begin(),intervals.end(),[](const vector<int> &a, const vector<int> &b){
return a[1] < b[1];
});
int ans = 0; //记录能选择多少个区间
int right = -1e5; //记录上一个集合的右端点
for(auto &interval : intervals){
if(interval[0] >= right){ //如果集合左端点 >= 左侧集合的右端点,则代表集合之间没有重叠
right = interval[1]; //更新右端点
ans++; //答案增加
}
}
return intervals.size() - ans; //总区间数 - 选择的区间 就是答案
}
};
sort函数用于将集合按照右端点从小到大排序,sort函数传入三个参数,分别为(起始位置,终止位置,排序规则),其中排序规则可以不写,缺省为less<T>()递增排序。对于C++20及以上版本,我们可以这么写:
class Solution {
public:
int eraseOverlapIntervals(vector<vector<int>>& intervals) {
//右端点从小到大排序
ranges::sort(intervals,[](auto &a, auto &b){
return a[1] < b[1];
});
int ans = 0; //记录能选择多少个区间
int right = -1e5; //记录上一个集合的右端点
for(auto &interval : intervals){
if(interval[0] >= right){ //如果集合左端点 >= 左侧集合的右端点,则代表集合之间没有重叠
right = interval[1]; //更新右端点
ans++; //答案增加
}
}
return intervals.size() - ans; //总区间数 - 选择的区间 就是答案
}
};
lambda 的参数用 auto在C++14引入,ranges::sort是在 C++20 引入的范围排序,等价于传统 sort(intervals.begin(), intervals.end(), …),写法更简洁。
学习低版本的语法是为了巩固基础知识,同时也更好的适应算法竞赛,学习高版本的语法是为了让代码的可读性更好,写代码时更加丝滑,在后面的练习中,我也会尽量加入不同版本的语法来供大家比较学习。
-12.LeetCode 23.合并 K 个升序链表
Part 3:分治
挖一个坑在这里!
Part 4:回溯
📕回溯
🖊回溯练习
-16.LeetCode 46.全排列
对于本题,我们不难看出以下性质:
- 全排列中的所有可能排列,其内部元素数量必定和原数组相同
- ans的类型是vector<vector<int>>,ans内部元素perm的类型为vector<int>
- 最后返回的ans,内部元素个数是(nums.size())!,也就是原数组nums元素个数的阶乘
- 显然我们需要遍历nums中的数字来判断其是否可以放进perm中,但使用过的数字必定不能再次放进perm中,所以我们需要进行剪枝,通过辅助状态——开辟一个used[]数组,判断每个元素是否被使用过,可以大大提高效率
接下来我们直接看看代码:
class Solution {
public:
vector<vector<int>> permute(vector<int>& nums) {
int n = nums.size();
vector<vector<int>> ans; //答案数组
vector<int> perm; //ans中的元素
vector<bool> used(n); //辅助状态
traceback(perm,n,ans,nums,used);
return ans;
}
/*↓核心函数↓*/
void traceback(vector<int> &perm,int &n,vector<vector<int>> &ans,vector<int> &nums,vector<bool> &used){
if(perm.size() == n){ //通过性质1.易知
ans.push_back(perm); //压入答案数组中
return; //回到上一个选择分支
}
for(int i = 0; i < n; i++){
if(used[i]) continue; //如果这个数字被选择过,则跳过它
perm.push_back(nums[i]); //否则加入perm中
used[i] = true; //更新辅助状态
traceback(perm,n,ans,nums,used); //递归调用
used[i] = false; //回溯更新状态
perm.pop_back(); //回溯更新状态
}
}
};
C++11不支持 lambda 的参数用 auto,也不支持“通用 lambda 递归” 这种语法,但对于C++14及更高版本,我们可以这么写:
class Solution {
public:
vector<vector<int>> permute(vector<int>& nums) {
int n = nums.size();
vector<vector<int>> ans;
vector<int> perm;
vector<bool> used(n);
auto traceback = [&](auto && self){
if(perm.size() == n){
ans.push_back(perm);
return;
}
for(int i = 0; i < n; i++){
if(used[i]) continue;
perm.push_back(nums[i]);
used[i] = true;
self(self);
used[i] = false;
perm.pop_back();
}
};
traceback(traceback);
return ans;
}
};
杂谈
1.数论—关于数根
数根又称数字根(Digital root),是自然数的一种性质,每个自然数都有一个数根。对于给定的自然数,反复将各个位上的数字相加,直到结果为一位数,则该一位数即为原自然数的数根。如369的树根计算方式如下:3+6+9=18,1+8=9,即369的树根为9。
总结规律,假设自然数num的十进制表示有n位,从最低位到最高位依次是a₀到aₙ₋₁,则num可以写成如下形式:
显然,对于任意非负整数 i,10ⁱ – 1 = 0都是 9 的倍数。由此可得 num 与其各位相加的结果模 9 同余,num与其数根模 9 也同余。
讨论 num 情况
- num 不是 9 的倍数时,其数根即为 num 除以 9 的余数。
- num 是 9 的倍数时:
- 如果 num = 0,其数根是0;
- 如果 num > 0,则各位相加的结果大于0,其数根也大于0,因此其数根是 9。
结论:num的数根 = ( num – 1 ) % 9 + 1;
2.一般定长滑动窗口板子
在一数组 arr 中对一定长为 k 的区间进行处理,使用滑动窗口模型,注意边界处理问题,以及左右边界的更新。
class Solution {
public:
int title(vector<int>& arr, int k, auto other_Info) {
int count = 0;
for(int i = 0; i < k; i++){
//先对 count 的 0 ~ (k-1) 这个区间进行处理,
}
int ans = 0; //答案计数器
if(/*满足某个条件*/) ans++;
for(int i = 0, j = k - 1; j < arr.size() - 1; i++, j++){
//更新左右边界
count /* 处理 */ arr[j + 1];
count /* 处理 */ arr[i];
if(/*满足某个条件*/)ans++;
}
return ans;
}
};